Search the Community
Showing results for tags 'automate'.
Found 5 results
-
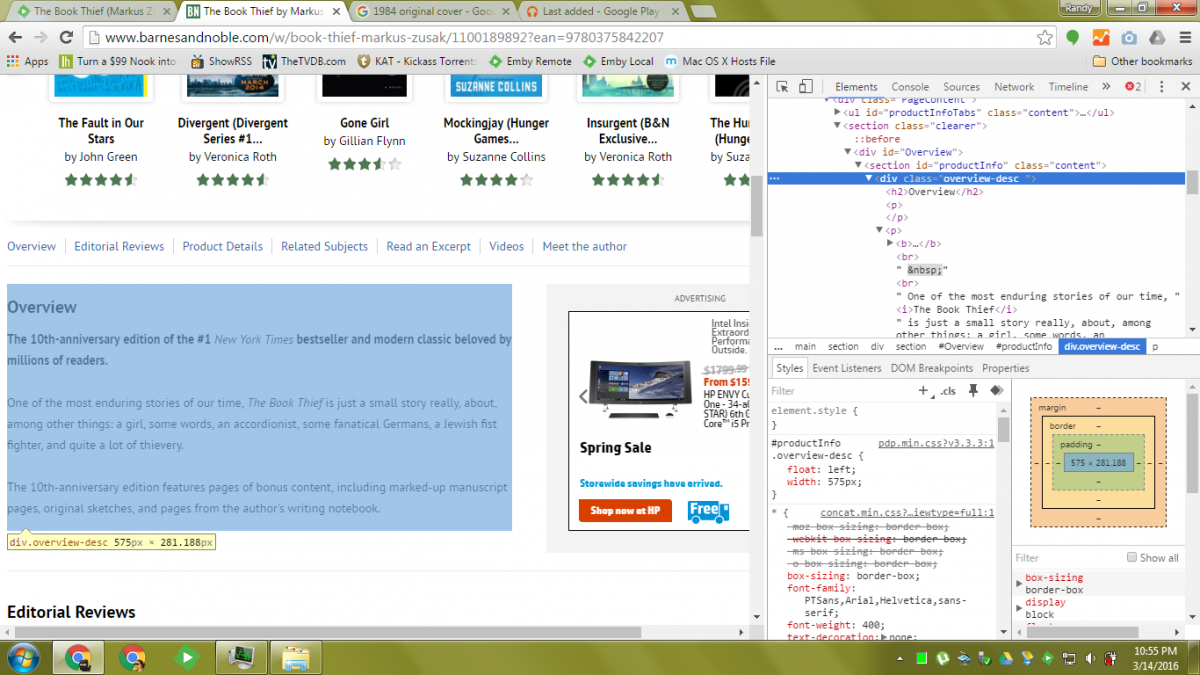
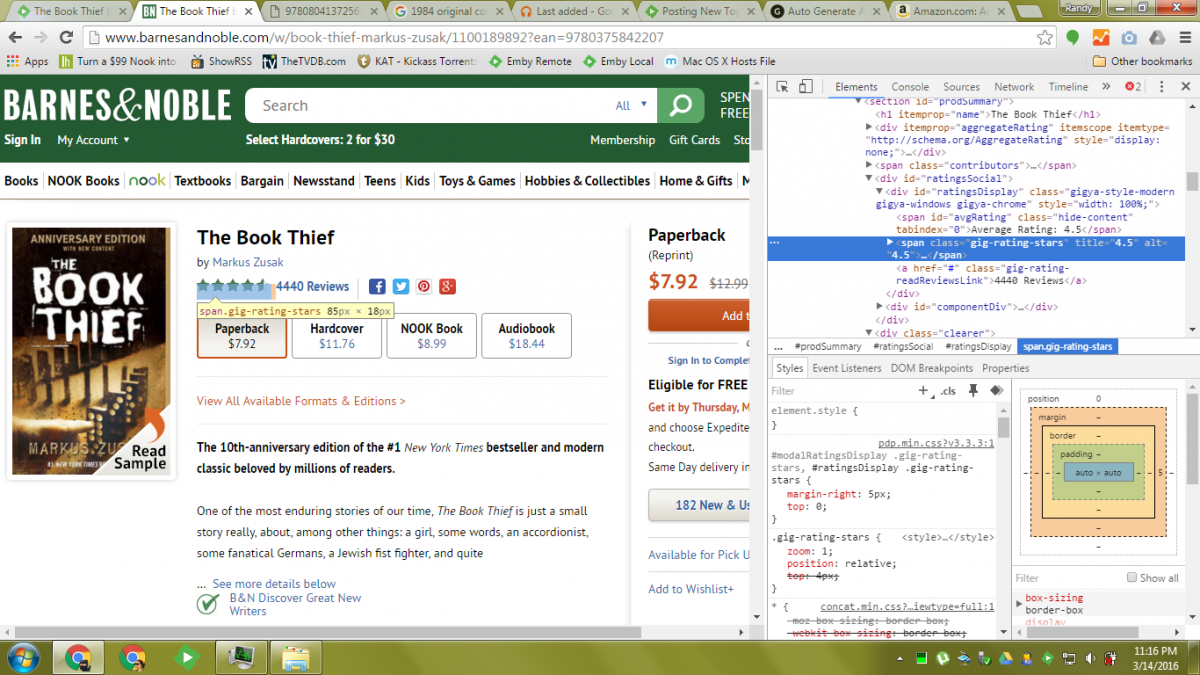
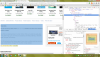
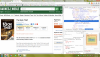
So I wish I had the time or pre-existing skills to write a plugin here. I know several languages, but alas... nobody wants my life story. My hope is that someone already involved in plugin development or development in the main server will be inspired by this idea. If Ebooks can be "identified" through Emby with their ISBN, I can logically see a plugin/feature of Emby that would take the following information, generate the appropriate URL, parse the URL for a specific div, and copy the contents of that div into various metadata fields. For instance... The Book Thief by Markus Zusak... BOOK OVERVIEW (see attached screenshot) http://www.barnesandnoble.com/w/book-thief-markus-zusak?ean=9780375842207 URL format: "http://www.barnesandnoble.com/w/" + full-title + author-first-last + "?ean=" + isbn13 Inside this page, copy contents of div.overview-desc, stripping out the h2 tags and their contents note: isbn13 from above is stripped of hyphens BOOK COVER IMAGE http://prodimage.images-bn.com/pimages/9780375842207.jpg simple url format: "http://prodimage.images-bn.com/pimages/" + isbn-13 + ".jpg" note: isbn13 from above is stripped of hyphens ------------------------------------ Of course, this may need to be built into Emby Server in order to integrate the "identify" feature as seen in movies, television, etc. But the ISBN could always be manually input into the "website" part of the metadata, or the "comic vine volume id" since these ebooks aren't going to be in their database. This process can be duplicated for other information as well... Star ratings (see attached screenshot), reviews, and most other sites. As long as those sites are database driven, we can find that pattern. I'd love to help, but time is in short supply.
-

Automatically Refresh Episodes with Placeholder Titles With Scripter-X
SuperMinecraftKid posted a topic in General/Windows
Don't you hate having your nice library ruined by a stray episode with the title "Episode XX" or "TBA" because that data wasn't available at the time it was scanned in? Well I may have a solution that uses python, emby api, and scripter-x to collect these episodes and automatically refresh their metadata until an actual title is found. Check it out here https://github.com/stummyhurt/noTBA-scripterx -
I feel like I must be missing something basic here, but I only seem to be able to tag an individual movie or series to be converted. All media I'm downloading is coming in as MKV 720p x264. I'm able to convert to MP4 same quality quite quickly and efficiently using the auto convert function because all I'm really changing is the container, however I'd like to set a rule so that ALL media under Movies and TV Shows are automatically converted, including new series and all movies, without me having to manually create a conversion rule for each of them. Is this possible? Am I missing an obvious setting somewhere?
-
https://github.com/travman1900/DroneFactoryReplacement check this out!
-
Hey Guys, I am trying to setup Sickbeard to automate my TV shows and downloads. Sickbeard looks for an NFO/XML file in the setup folders. I have created mine and directed to each season folder. Is there a file in there that Sickbeard can read from so it knows which is the next episode to download?