Search the Community
Showing results for tags 'fetch'.
Found 3 results
-
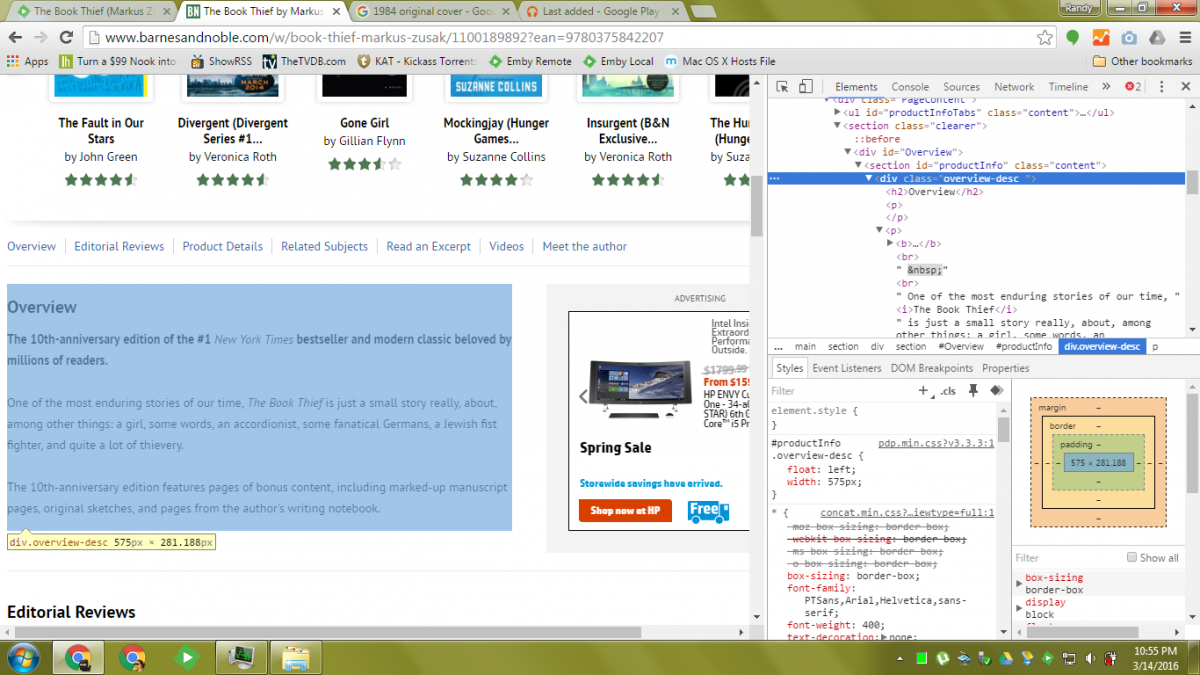
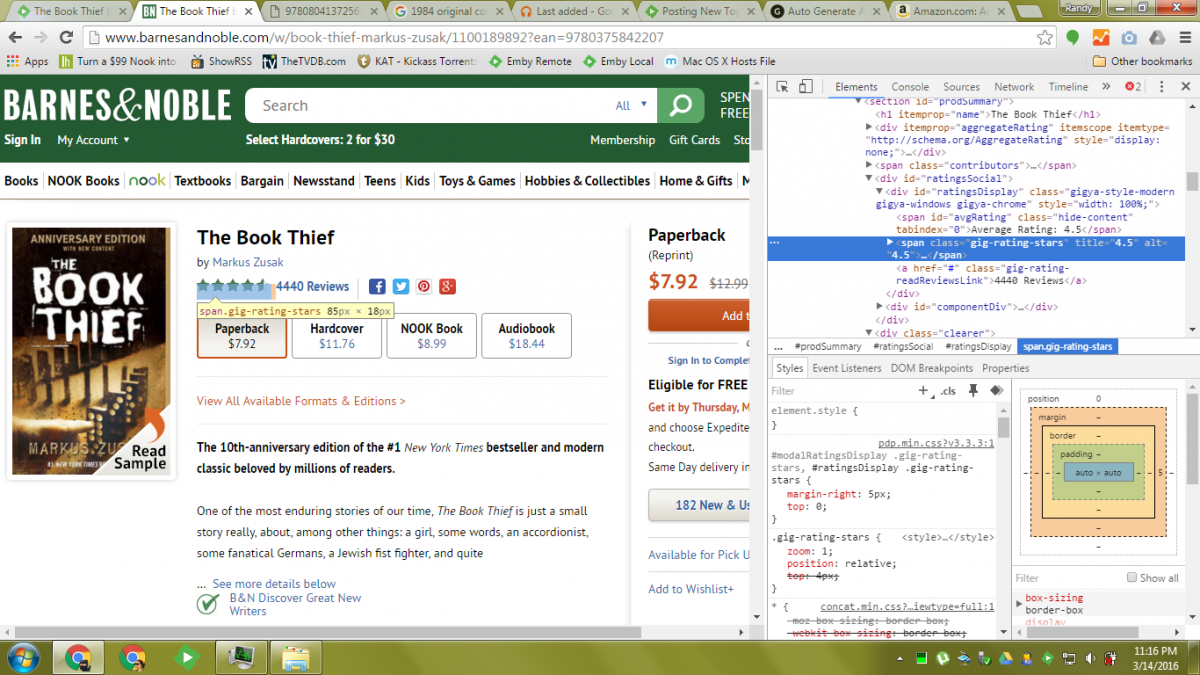
So I wish I had the time or pre-existing skills to write a plugin here. I know several languages, but alas... nobody wants my life story. My hope is that someone already involved in plugin development or development in the main server will be inspired by this idea. If Ebooks can be "identified" through Emby with their ISBN, I can logically see a plugin/feature of Emby that would take the following information, generate the appropriate URL, parse the URL for a specific div, and copy the contents of that div into various metadata fields. For instance... The Book Thief by Markus Zusak... BOOK OVERVIEW (see attached screenshot) http://www.barnesandnoble.com/w/book-thief-markus-zusak?ean=9780375842207 URL format: "http://www.barnesandnoble.com/w/" + full-title + author-first-last + "?ean=" + isbn13 Inside this page, copy contents of div.overview-desc, stripping out the h2 tags and their contents note: isbn13 from above is stripped of hyphens BOOK COVER IMAGE http://prodimage.images-bn.com/pimages/9780375842207.jpg simple url format: "http://prodimage.images-bn.com/pimages/" + isbn-13 + ".jpg" note: isbn13 from above is stripped of hyphens ------------------------------------ Of course, this may need to be built into Emby Server in order to integrate the "identify" feature as seen in movies, television, etc. But the ISBN could always be manually input into the "website" part of the metadata, or the "comic vine volume id" since these ebooks aren't going to be in their database. This process can be duplicated for other information as well... Star ratings (see attached screenshot), reviews, and most other sites. As long as those sites are database driven, we can find that pattern. I'd love to help, but time is in short supply.
-

Album Fetch Fails (Automatically) on Foldername, Succeeds (Manually) on Album ID3tag
ginjaninja posted a topic in General/Windows
When adding an album with id3tag "Seeking Major Tom" to the filesystem as foldername W:\Music\William Shatner\(2011) Seeking Major Tom, the fetch is performed on the folder name and fails. 2014-08-16 13:07:42.1543 Info - App: HttpClientManager GET: http://www.musicbrainz.org/ws/2/release/?query="(2011)+Seeking+Major+Tom" AND arid:a406a684-7c88-442b-836d-3b9b67bbc91d later when refreshing the album object manually the fetch is performed against (what i assume is) the id3 tag and works. 2014-08-16 13:21:36.8830 Info - App: HttpClientManager GET: http://www.musicbrainz.org/ws/2/release/?query="Seeking+Major+Tom" AND arid:a406a684-7c88-442b-836d-3b9b67bbc91d is this expected behaviour? -
https://dl.dropboxusercontent.com/u/84611964/server-63522732798.log Version 3.0.5097.16641 example in log, big trouble in little china mb3 configured to manage all metadata and store locally in collection. Every film which i delete all backdrops for....has its backdrops redownloaded (good) but 2 of every instance (bad - should be 1) (Note i deleted backdrops as i noticed duplicates of backdrops in movies that i checked)