
Search the Community
Showing results for tags 'parsing'.
Found 2 results
-
There‘re so many cases that I can not receive the right answer for the show I want to search, with my local language. The string I input is right in the tittle of that show, still no answer returned, it only works when I input the string beginning with the first characters. It doesn't make sense I still need to memorize the title from the beginning when a searching engine is right there. Example: 君主·埃尔梅罗二世事件簿 魔眼收集列车 Grace note No answer returned using words in the middle like "二世", “列车”, but the beginning word "君主" or English word "grace" which even is not at the beginning.
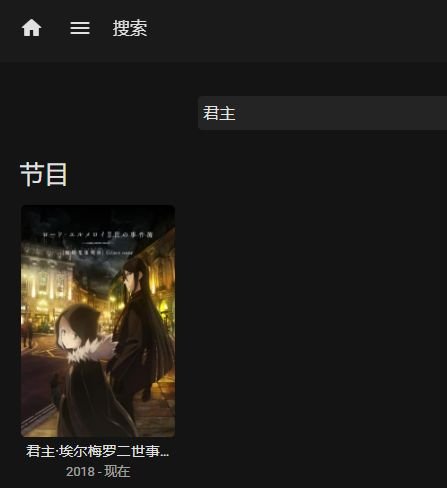

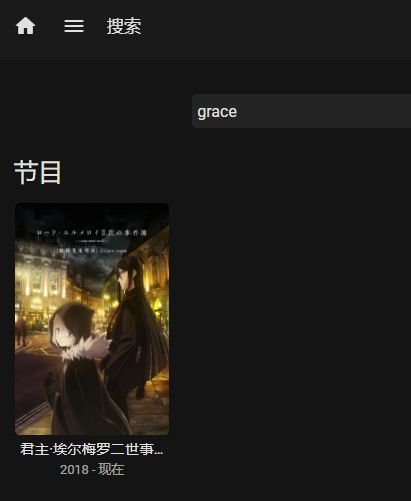
-
Hello Emby Community, I'm using m3u2strm python script to parse my m3u. I have it setup with windows scheduler as well. This issue I'm having with one of my tv series m3u is the process is breaking at the show "#Black". I know # tells python to comment out. How can I get around this issue or ignore it during the parsing process without having to manually edit the m3u myself? The scheduler is set to run every night at midnight, so the m3u is downloaded every night and updates back to the "#Black". I need a way to either edit or ignore during the automated download and parsing process. Thanks in advance for all help or suggestions. https://drive.google.com/drive/folders/1JLqn_Ix7fnHSQscW8LhIuoh8qn2i5ZI2?usp=sharing
_1.thumb.png.52270e3df3f24959a4cd032d404c17a5.png)
